Resumo
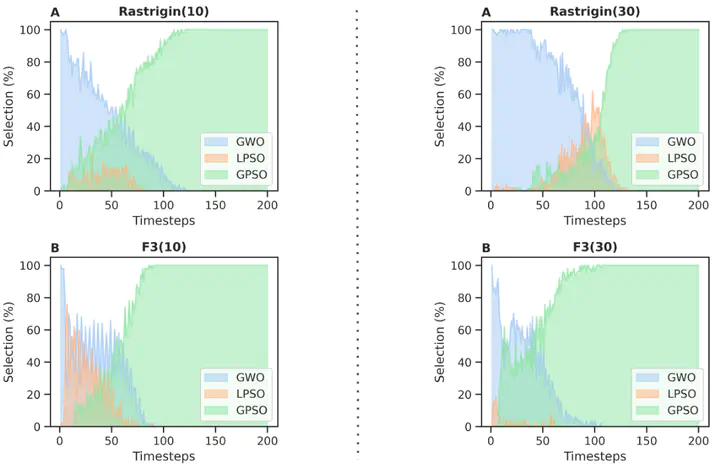
Swarm intelligence is a very efficient field for the optimization of high-dimensional functions. Nevertheless, choosing the best swarm-based algorithm is still challenging because it requires expertise in the field. Here, we propose to use reinforcement learning to dynamically select the swarm-based techniques to solve a benchmark function based on the current simulation state. First, we created a swarm capable of modifying its metaphor over iteration. Next, we created a reinforcement learning environment to solve benchmark functions. Then, we trained Proximal Policy Optimization to select the well-suited metaheuristic (GWO, GPSO or LPSO) to solve Rastrigin and F3 based on the information retrieved from the simulation. Our proposal reached competitive results in all simulated scenarios. Moreover, we found that the use of GPSO is consistently more efficient at the middle of the convergence and that using GWO is more efficient than using the other selected algorithms at the beginning of the convergence. Future works will bring us more robustness in combining swarm-based techniques while decreasing the computational cost. Thus, we show that reinforcement learning has the potential to overcome the effort of choosing the well-suited metaheuristic for a specific problem.
Rodrigo Lira
Professor
Rodrigo Lira é professor no IFPE e tem interesse nas áreas de inteligência de enxames, aprendizado de máquina e IoT.